
Snowflake is a database built from scratch from the cloud – as a result, unlike others that were not, they were able to start without the burden of any traditional architecture and make the best no compromise decisions in designing the Snowflake architecture. This is a much better place to be in than taking something traditional and trying to port it to the cloud, as it comes with a legacy burden and core code that must be worked around or massively reworked.
Whereas traditional shared nothing databases still had processing and storage coupled, they have since been decoupled in the cloud, theoretically allowing bottlenecks of data scan speed or data compute to be addressed separately.
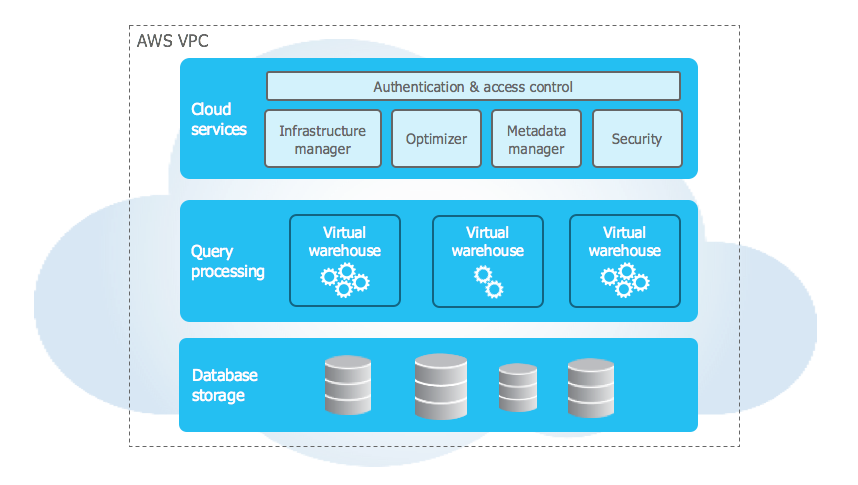
Snowflake has an area of centralized storage, atop of which virtual warehouses are built to interact with its storage. This could just be one single large warehouse for production – as would typically be done on site – however since they interact with the same data, one of the most awesome features about snowflake is being able to decouple the compute and size it based on use and need. ETL resources no longer need to compete with user production queries, as a separate virtual warehouse compute environment can be constructed for each.
In the image above, we can see the grey virtual warehouses surround the centralized storage – each getting their own compute – as well as read/scan resources. A full table scan by the development team against this data only has an effect in their own warehouse – to the ad-hoc analytics group, this work goes completely unnoticed.
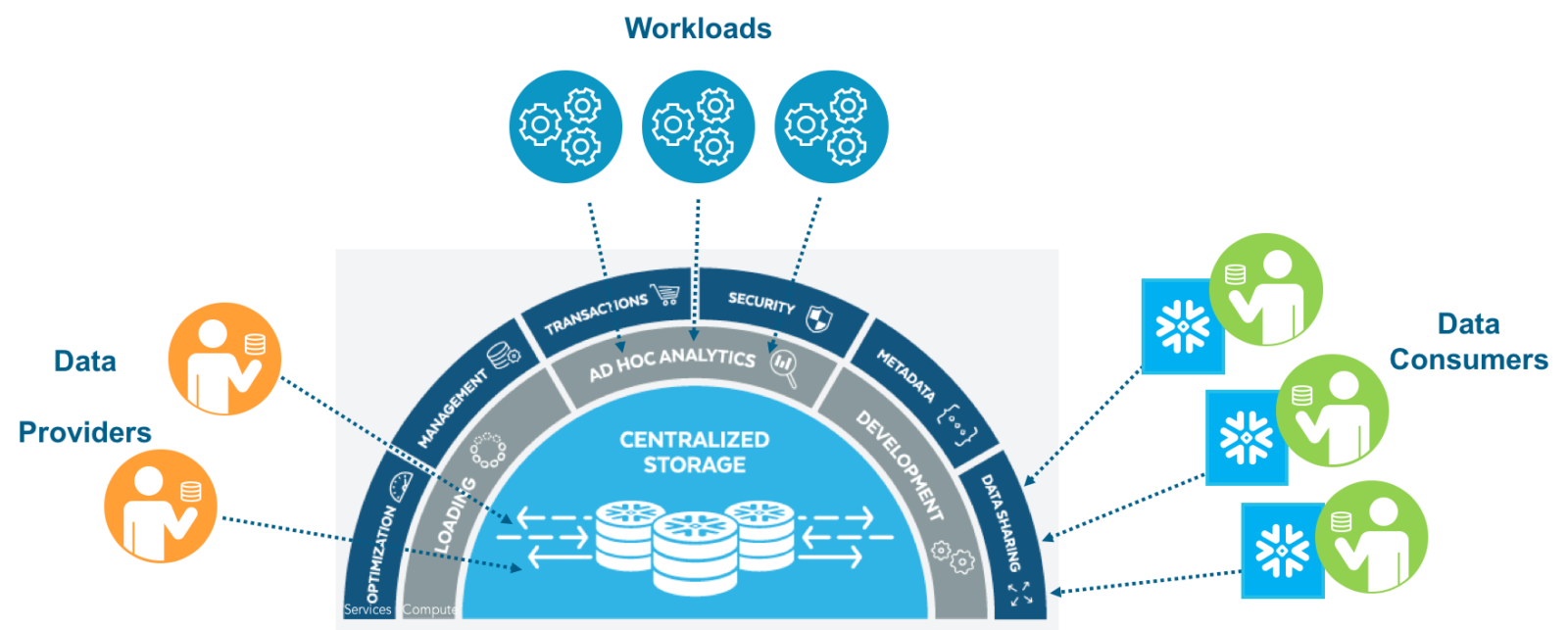
I modeled the below architecture diagram off a slide I liked. Some may recognize the stencils as actually coming from Azure. Currently Snowflake is only offered on Amazon, however my understanding is that Azure is in the works as well, so hey, they work well! As Snowflake is a cloud database, it’s able to constantly evolve and upgrade as well; without something as challenging as performing a hardware migration in one’s own production environment. To the best of my knowledge, here’s the current architecture and a little more about how it works.
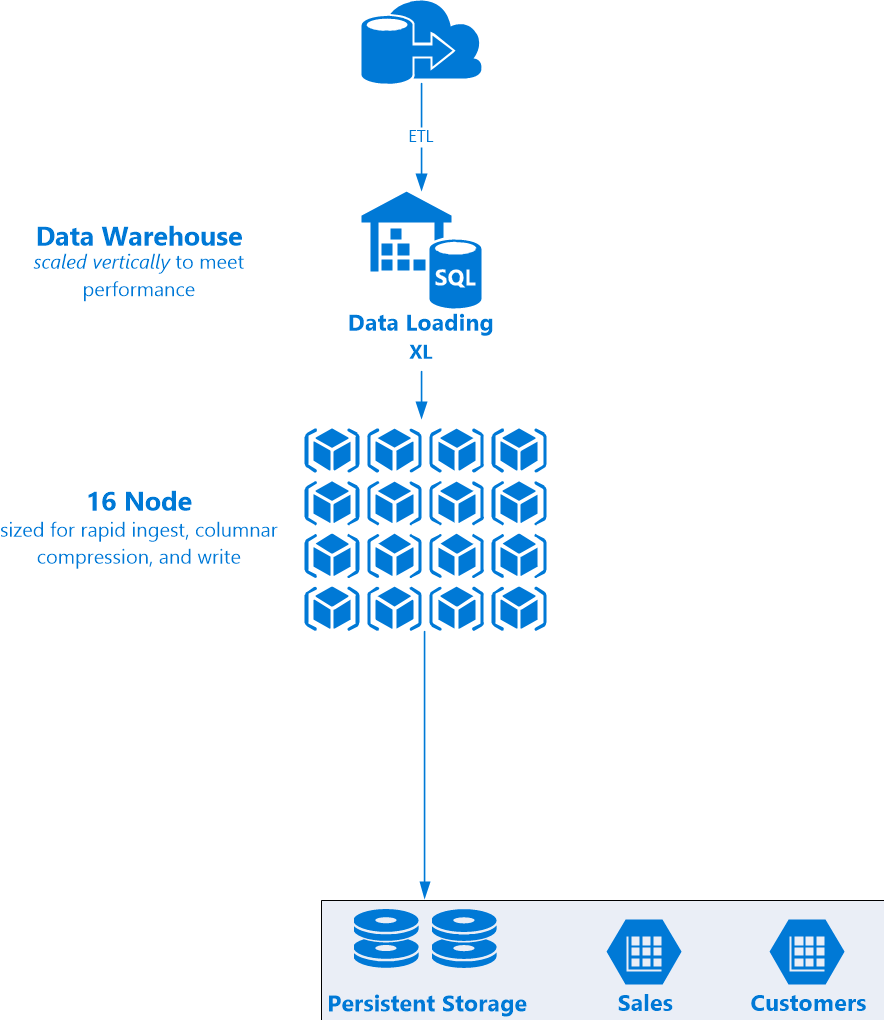
It’s easiest to logically break this Snowflake architecture up across the roles we’re doing here; ETL (or ELT) and reporting. Let’s start with the former. We’re loading data from our source systems into Snowflake, and want to do so quickly; columnar compressing a large amount of data is a compute intensive job. Although it’s compressed, while writing a lot of data we want a large amount of disk available to write it in quickly. We’ll vertically scale this job to a large virtual warehouse; an Extra Large (XL) in this case with 16 nodes. Note that the databases scale fairly linearly, and the current cost is a credit per node; this means that 60 minutes of a 4 node system will cost the same as 15 minutes of a 16 node system. So why not scale her up and get the job done? The warehouse can be spun down to a small or even suspended after the work has been completed. To support independent reads from each virtual warehouse, as well as for redundancy and fault tolerance, the same data is written to/replicated at the storage level – although one only pays for the single copy of the data.
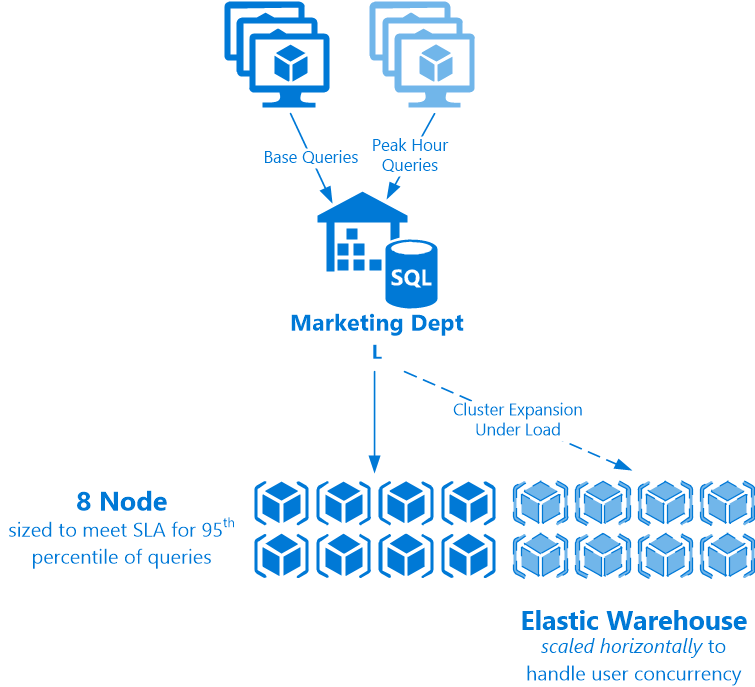
On the reporting side, we have the much more interesting path of querying our reporting warehouse and handling user load. How does this work? This virtual warehouse was vertically sized to a Large (L) size with 8 nodes. With some testing it was found to hit the target SLAs 95% of the time for a given workload, ie. size Large means 95% of our queries hit 10 seconds or less, the requirement to hit per the business line. This may be what the system experiences during the early morning, but what about when everyone is on using it in the afternoon? Or for month end process? It could be scaled up vertically – this will result in faster atomic queries, which will reduce overall concurrency by nature of less overlap of queries. However the system has cluster growth controls in the Enterprise version of Snowflake to more elegantly scale the system horizontally – by dynamically growing (and shrinking) a multi-cluster environment to handle the increased load as long as the demand is still available. This avoids having to deal with a single cluster vertical up/downsize problem, and allows for a more consistent user experience. The 10 second query doesn’t sometimes occasionally run in 5 seconds or 15 seconds; it just pretty much always runs in 10 seconds. It is also much easier to keep scaling horizontally to handle any amount of incoming user workload.
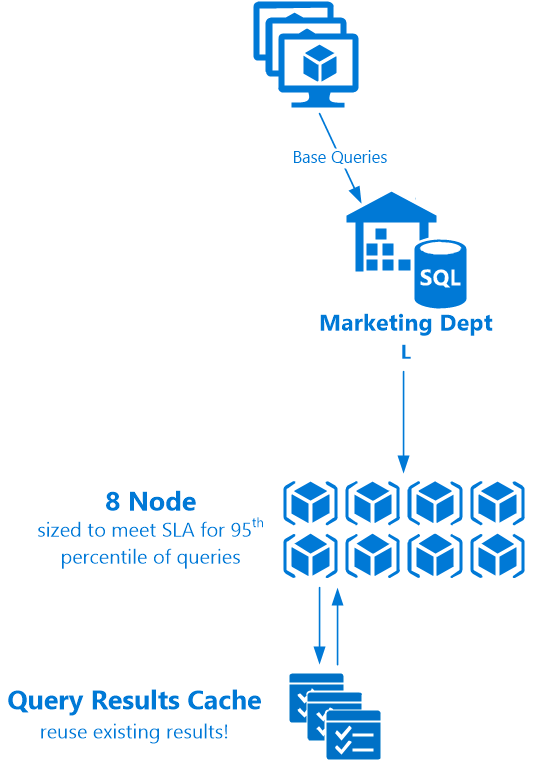
Onto querying; unlike many databases that expect results caching to be done at a reporting or BI tool layer, Snowflake actually provides them at the database level! This is an awesome feature. If you or a colleague have already asked the same question, and the data has not changed, Snowflake simply returns to you the already existing resultset. This relieves a lot of burden on the database resources, particularly for more intense queries. Per the great Snowflake doc, the query results are persisted for 24 hours – reset each time the results are accessed, for up to 31 days. Furthermore the results cache has no size limit and is persisted at the storage layer – an active virtual warehouse does not even need to be running to retrieve the results; this can even be done through a suspended warehouse!
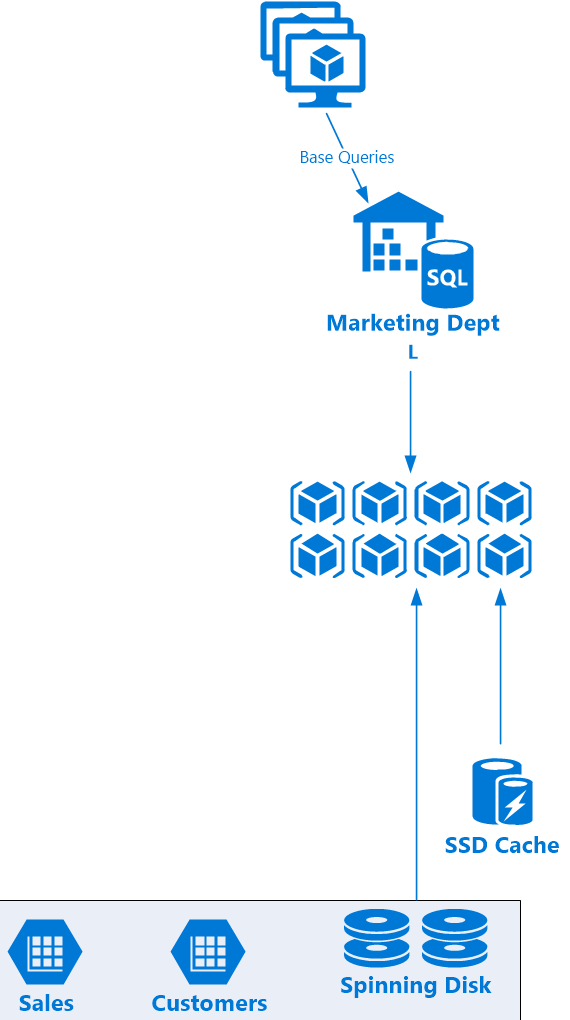
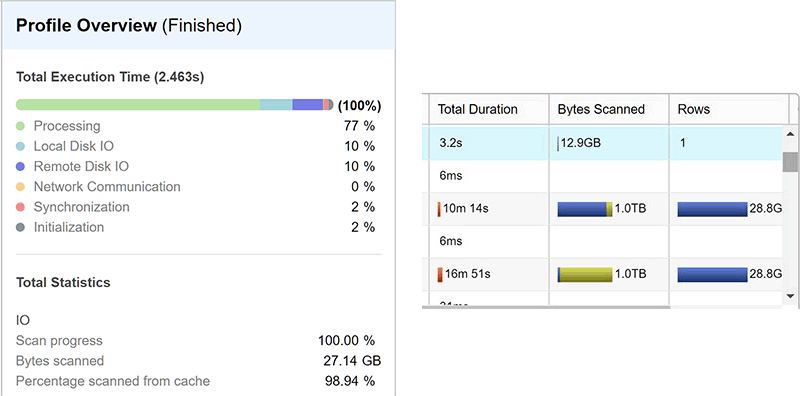
For those queries we run, data must be pulled from core disk. However, we also have a data cache of SSDs in the Snowflake architecture (in actuality, local to each server node I believe.) So for the data that we are accessing frequently, we get a great scan speed boost by having this data accessible both more locally as well as from much faster storage media. This gives a significant tangible boost to query performance for “hot” data. All other data we must pull from the core storage layer, Amazon S3 at present. What’s also great is that in the query profiler, we can see exactly how much data we’re working with and where it’s coming from as well. It’s on both the history tab (bytes scanned in blue) as well as query profiler (local vs. remote IO) steps.
Putting this all together, the architecture looks likes this.
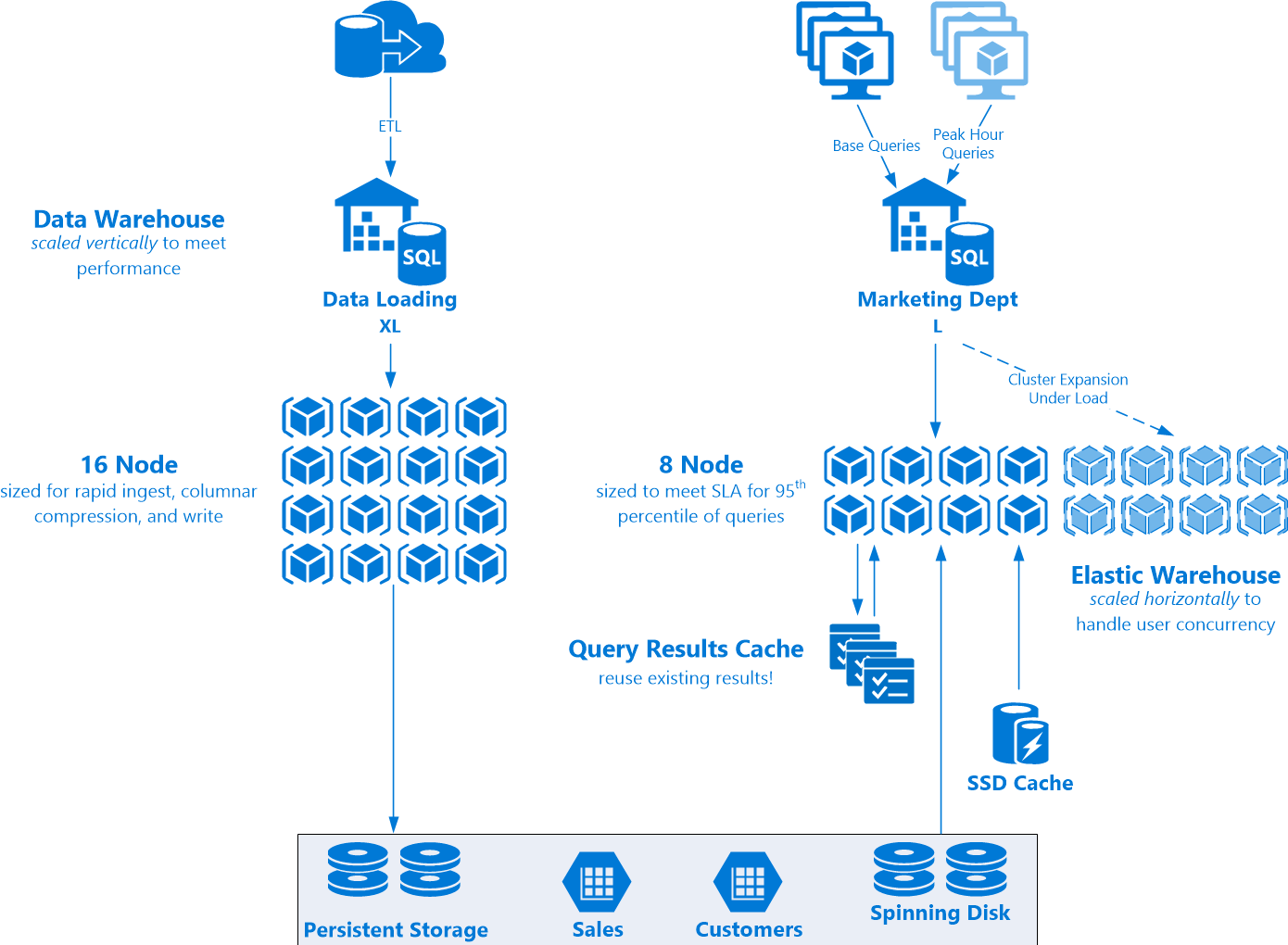
I think the Snowflake architecture is awesome. Not only can you scale vertically or horizontally to meet your needs, it’s built in as a very normal thing to do, and goes both ways – I don’t know if any of their competitors can say that. On top of that, the benefits from the SSD caching and the query results caching are both very real and significant. The ability to separate and size virtual warehouses based on workload and have them perform completely independently of one another against the same data is awesome, and certainly not a feature available in any kind of on site massively parallel database. An awesome architecture and big round of applause for the Snowflake team!
Stay connected