

{kind=link}
I’ve read that Snowflake clustering helps improve join speeds, although I’m not sure how just being in order would make that the case exactly. I’m going to try some tables to get a decent demonstrable fact-dimension join; sf1000 lineitem (6 billion rows, 169 GB) and sf1000 part (200 million rows, 5 GB). I’m going to order lineitem on orderkey, partkey, then make another copy doing it by partkey, orderkey. I’ll join the full tables, and then restrict on some parts and join the tables. My initial expectations are that the full table join won’t change any, but the partial table join will, because the small number of parts identified will be able to be pushed to the scan and prune lineitem. Note my test does not use structurally clustered tables, but simply ordered tables. What happened?
select avg(l.L_QUANTITY) from lineitem_part_ord l, snowflake_sample_data.TPCH_SF1000.part p where l.l_partkey = p.p_partkey and (p.p_partkey in ( 57619905, 57619906, 57619907, 57619908, 66666009, 66666407, 127941246, 127941273, 44451652, 44451700, 186154422, 186155441 ) or p_name = 'floral lemon sandy drab indian' or p_name = 'smoke snow burlywood frosted maroon' or p_name = 'orchid lemon misty gainsboro wheat' or p_name = 'rosy plum cornsilk thistle forest' or p_name = 'goldenrod lace chiffon saddle cyan' );

I don’t know how snowflake actually executes joins and distributes the work among its nodes, but it’s clear the orderly micro-partitions made a difference even on the full table join. Can we tell why this is from the query profiles?
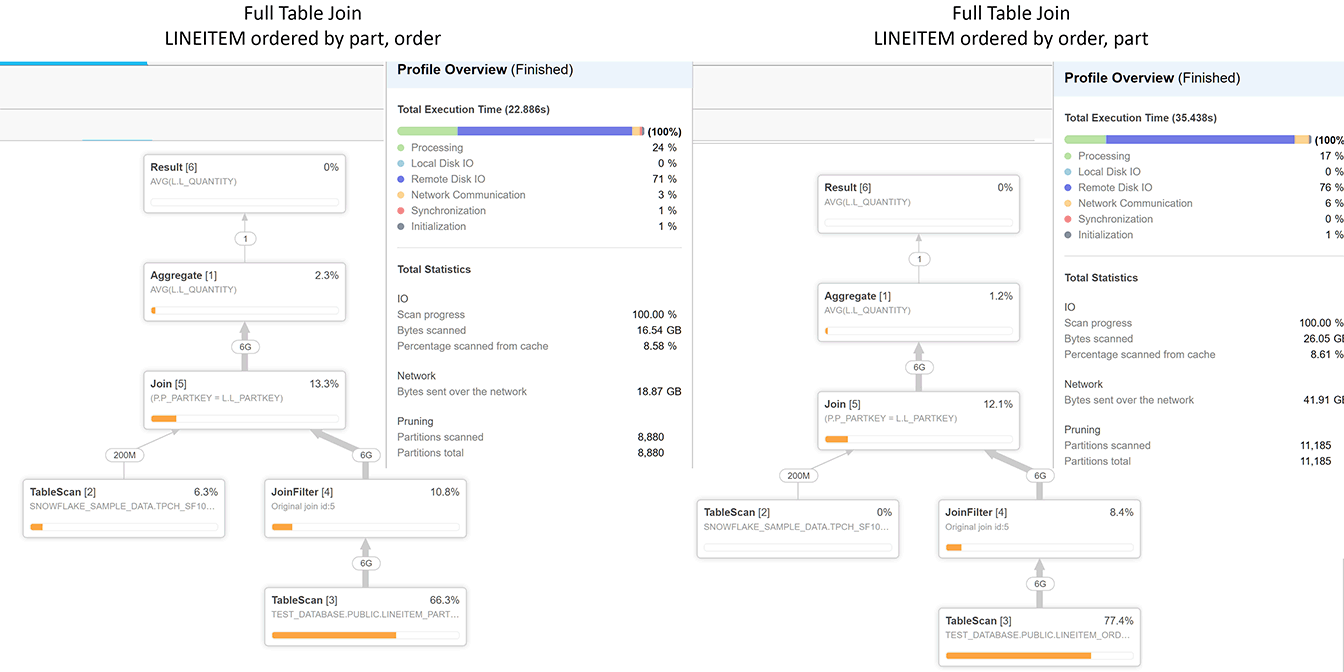
Well, we have the same plan. However we can see we spent more time reading and moving data for the table ordered by orderkey first, and read more partitions. Looking deeper, the tables have a fair difference in size after compression.

The profile lets us look at individual plan components – and the join in fact takes the same amount of effort. So the join itself is certainly not faster. The scan and filter actually tell us what is going on, for each the full and partial table scans; here’s what is going on against the two versions of lineitem:

Full table case: Ordering by partkey compressed the table a lot better than orderkey; the latter is a much higher cardinality key in this table. Furthermore, the orderkey is not complimentary to a partkey like a date might be; it is more competitive. By that I mean dates would have a lot of overlap of alike values, whereas orderkey will certainly not. It’s nearly a surrogate key on a fact table here. There certainly are not going to be many shared instances able to fill up entire 15 MB partitions. So we are simply dealing with the physics of reading a larger table here. What is interesting is the JoinFilter stage contains the exact same data although we see the larger table having much more data being moved still – so it would seem an uncompress, at least in this instance, isn’t happening until the join. It is at the join stage where both profile show the same value of 4.23 GB of data being sent onward over the network.
Part key restrict case: In the table ordered by item, we saw the best case scenario of pruning, down to just 6 micro-partitions read. Nice. On the other? The simple order and the nature of the data was so poor for clustering, that we did not in fact achieve any reduction through partition pruning! The JoinFilter in this case had to spend time throwing away a bunch of extra stuff we had to read. Ultimately it passed just the 525 records that might join onward – but it had to do a ton more work in the table ordered by orderkey. Note I picked this key somewhat randomly, but it makes a good and interesting point. Arguably a little better pruning could go on if I actually clustered the table by it rather than just sorted by it.
So does clustering improve joins? Not directly… but
- Join (and overall) work will generally be expected to improve as it compresses better and less data need be scanned or moved around; although one should probably not architect the design/load of a table to simply maximize compression.
- If the join key is clustered and a limited amount of records are filtered on, it can improve the join by reducing scan speed times for the join tables involved; most likely this would be the scenario of a dimension surrogate key in a fact table.
Your other ways to improve join speed are the standards; scale up the size of your servers, and make sure the appropriate joins are being used, ie. an inner join rather than a left join wherever possible. I’ve noticed some users, when given the ability to write their own sql/generated sql (SAS for example) are quite left join happy.
Stay connected